Base de données
Structure des topologies
Les topologies sont stockées sous forme de chaînes de caractères au format YAML. La structure de cette chaine est simple, elle est composée de 4 parties :
- name : le nom de la topologie -> utilisé pour identifier la topologie à la place de son ID, beaucoup trop lourd pour l’utilisateur
- vlans : la liste des VLANs utiles à l’application de la topologie, à créer si nécessaire
- interfaces : la liste des configurations des interfaces de la topologie
- trunks : la liste des configurations des trunks de la topologie
Un exemple de topologie est proposé en annexe 5
Comment sauvegarder une topologie
Tout d’abord, il a fallu faire un choix au niveau de la technique de stockage de ces données. Nous avions plusieurs solutions :
- Les stocker sous forme de fichiers YAML, dans un dossier spécifique sur le serveur
- Les stocker dans une base de données
Nous avons choisi l’option de la base de données, mais là encore, beaucoup de choix se sont offerts à nous. Lors de notre cursus à l’IUT, nous avons étudié le système de base de données PostGreSQL, qui est un système relationnel, c’est à dire que les données sont stockées dans des tables, qui sont liées entre elles. Cela impose un format de données assez statique, sans compter la conception de la structure de la base. Nous sommes donc partis sur une base capable de stocker des données au format clé/valeur (JSON), MongoDB. MongoDB nous permet de stocker nos topologies quasiment tel quel, sans devoir les formater, pour les faire rentrer dans des tables. L’avantage de ce système, c’est qu’à un identifiant, est lié une topologie, ce qui est bien plus simple pour la gestion de la base, mais aussi les lectures et écritures dans celle-ci.
Interactions avec le gestionnaire de topologie
Lorsque nous avons commencé le projet, nous sommes partis sur une API, gérant l’ensemble des opérations liées à la base de données, à l’actif, et à l’authentification. Le système que nous avons développé n’implique donc pas une communication directe de la base de données avec le gestionnaire de topologie, mais uniquement avec l’API, qui interface la base et la partie interface utilisateur.
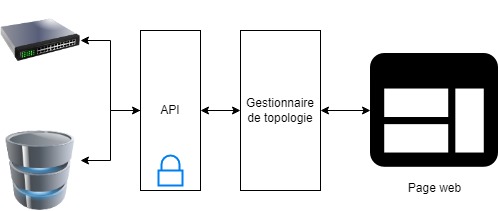 La logique derrière ce choix, était de se rapprocher le plus possible de l’architecture des logiciels en production aujourd’hui.
La logique derrière ce choix, était de se rapprocher le plus possible de l’architecture des logiciels en production aujourd’hui.
Néanmoins, avec le recul et grâce aux discussions que nous avons eu avec notre tuteur de projet, nous nous sommes rendu compte que nous avons ajouté de la complexité au projet, et qu’il aurait été plus simple de faire dialoguer le gestionnaire de topologie directement avec la base de données. Ce choix concorde malgré tout, avec celui de déléguer la responsabilité de l’application des topologies à l’API. C’est pour cela que nous n’avons pas fait marche arrière et que nous sommes restés sur cette architecture.
Stockage des utilisateurs
A l’origine, les utilisateurs aussi, étaient stockés sur la base de données. Elle était consultée par l’API, qui gérait l’authentification. Cette architecture était assez complexe, et nous avons donc décidé de ne pas la conserver, puisque nous nous sommes encore une fois rendu compte que nous avions complexifié le projet. Nous avons donc décidé de stocker les utilisateurs dans un fichier YAML, et de déléguer la connexion des utilisateurs au gestionnaire de topologies. Cela implique aussi de rendre l’API ouverte, sans que l’authentification soit nécessaire, mais cela n’est pas handicapant, puisqu’à terme, celle-ci ne sera pas exposée.